摘要
随着前端数据采集设备精度的不断提高,对信息处理系统的实时性、准确性提出更高的要求。而从日趋完善的计算机体系结构中,半导体工艺难以取得重大突破的情况下,想要获取更高的计算性能(信息处理能力),我们就必须探索另外一条道路——并行处理。GPU在应用于图像处理领用,其CUDA平台的支持,对于浮点运算的高效,因而作为并行信息处理的技术被广泛应用。
关键词
GPU,CUDA ,并行信息处理
1. 并行处理技术
1.1 并行处理技术介绍
并行处理或并行计算是指利用多台计算机或处理器同时执行运算任务,从而减少解决问题所需要的时间。一般可分为时间并行计算和空间并行计算。
时间上的并行计算叫做流水线处理,即多个处理器按照处理时间的先后顺序执行计算;空间上的并行是指多个处理器同时执行计算,各处理器在时间上相互独立。并行处理技术主要研究空间上的并行,即通过总线方式将多个计算机或处理器并联,从而获得更快的处理速度。
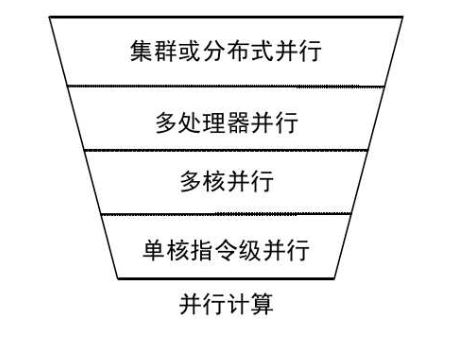
并行计算根据规模不同,分为一下几个层次。如图所示,最底层是单核指令级并行(ILP),即单个处理器,但可同时执行多条指令;其上为多核并行,即单芯片拥有多个处理器核心;再往上是多处理器并行,即通过多个芯片之间分工协作做到并行处理;最上层为集群或分布式并行,通过网络互联实现超大规模并行运算,可参考大型数据中心。
1.2 Flynn计算机体系分类
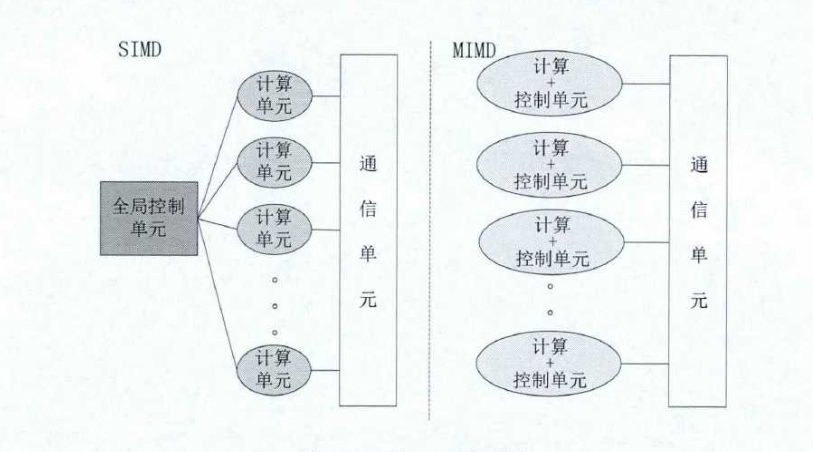
1966年,Flynn根据指令流和数据流的多倍性对计算机体系结构进行了分类。分为单指令流单数据流模式(SISD),单指令流多数据流模式(SIMD),多指令流单数据流模式(MISD),多指令流多数据流模式(MIMD)。其中SIMD和MIMD属于并行处理器。
SIMD和MIMD处理器结构示意图如图所示。SIMD只有一个控制单元,这个控制单元控制多个计算处理单元,这些处理单元共享存储器或信号进行通信。MIMD处理器拥有多个控制单元,每个控制单元控制自己的计算单元,通过共享存储器或信号进行通信。
2.CUDA GPU并行架构
CUDA是设备计算统一框架的简称(Compute Unified Device Architecture)。其目的是为了用C语言再GPU上进行编程,而无需关注图形API和GPU编程的知识。它可以运行和访问GPU设备的指令和存储空间,从而可以非常快速入门并且从GPU的并行计算中获利。再此之前,GPGPU编程需要针对特定的处理器,而不是标准的API,不能在不同GPU之间进行移植。在CUDA并行架构中,GPU被当作CPU的协处理器来运作,一些数据并行独立且计算密集的函数适合放入GPU中运行。

图为CUDA并行架构框图。底层为CUDA的组成部件,其包括:支持CUDA并行计算的GPU、支持CUDA的操作系统内核、用户模式驱动、PTX并行计算指令集。
在软件层次,CUDA提供了完备的软件开发环境,包括编译器、调试器、性能测评工具及基础库。并且支持C语言编程,从而可以支持其他高级语言,比如Java和Python。CUDA提供了两种编程接口:设备级编程接口和语言集成编程接口。
3. CUDA 硬件原理
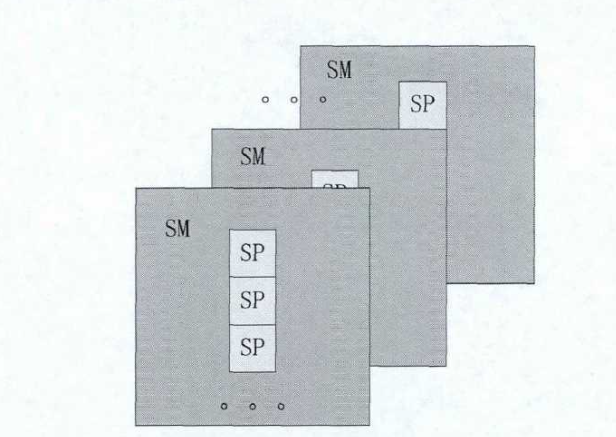
CUDA 硬件基础结构由一组多线程流处理器(SM,Multitreaded Stream Multiprocessors)的单元组成。如图所示,SM中又有多个SP(Stream Processors)负责具体运算。多线程流处理器SM被设计成拥有可以同时执行上百个线程的能力。为了获得同时执行这么多线程的能力,CUDA从SIMD结构上发展出单指令流多线程(SIMT, Single Instruction Multiple Thread)结构。
SM多线程处理器负责创建、调度和执行线程,这些线程以32个为一组,成为一个Warp。组成同一个Warp的单独线程从同一个程序地址执行。但是他们拥有单独的指令地址计数器和独立的存储器。所以他们可以互不干扰的运行各自的指令及分支。
当多线程处理器执行一个或多个线程块时,它把他们分为独立的Warp,之后由Warp调度器进行调度。线程块中的线程根据线程号线性的分组为Warp,即前32个线程号的线程为第一个Warp,接下来32个线程号为第二个Warp,以此类推。一个Warp内的线程每次执行一条指令,所以如果Warp里的32个线程在执行时执行相同的指令路径可以使效率最大化。如果一个Warp中的线程在执行过程中产生了分支,则Warp顺序执行完每个分支,直到所有分支都执行完毕后会和到同一个指令开始执行。不同的Warp各自独立运行,在一个Warp内产生的分支不影响其他的Warp。对于一个特定的线程块,它只能在一个多线程处理器(SM)中执行。但是一个多线程处理器可以执行多个线程块。